Solving Tic-Tac-Toe with Reinforcement Learning
Introduction
In this earlier blog post, I covered how to solve Tic-Tac-Toe using the classical Minimax algorithm. Here we will use Reinforcement Learning to solve the same problem.
This should give you an overview of this branch of AI in a familiar setting. As argued in this paper by pioneers in the field, RL could be the key to Artificial General Intelligence. Therefore, it would behoove us to better understand this fascinating field.
To see the full code, please refer to the notebook here. I will only focus on the results here, lest the blog become too code heavy.
Introduction to Reinforcement Learning
I will refer you to this post by someone way smarter than me if you want to really spend some time understanding Reinforcement Learning.
I will just skim the surface in this section. Feel free to skip this section entirely.
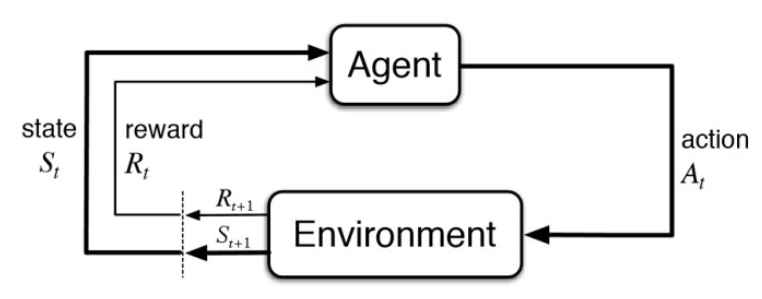
As shown in the figure above, the reinforcement learning framework comprises the following elements
- Agent : Entity learning about the environment and making decisions. We need to specify a learning algorithm for the agent that allows it to learn a policy
- Environment: Everything outside the agent, including other agents
- Rewards: Numerical quantities that represent feedback from the environment that an agent tries to maximize
- Goal reward representation: 1 for goal, 0 otherwise
- Action penalty representation: -1 for not goal, 0 once goal is reached
- State: A representation of the environment. At time step $ t $,the agent is in state $ S_t \in \mathcal{S} $ where $ \mathcal{S} $ is the set of all possible states
- Action: At time step $ t $, an agent takes an action $ A_t \in \mathcal{A}(S_t) $ where $ \mathcal{A}(S_t) $ is the set of actions available in state $ S_t $
- Policy: A policy tells the agent what action to take in a given state. $ \pi(a|S) $
A policy can be deterministic i.e. there is one action that is deterministically selected in a given state $ \pi(s)=a $, or stochastic i.e. the policy maps a state onto a set of probabilities for taking each action. $ \mathbb{P}[a^i|s] < 1 $ subject to $ \sum_i \mathbb{P}[a^i|s] =1 $
To solve a problem using RL, we should be able to formulate it as a markov decision process (MDP).
Markov Decision Process
In an MDP, the environment is completely characterized by the transition dynamics equation
$$ p(s’,r|s,a) $$ That is, the probability of each possible value for $ s’ $ (the subsequent state) and $ r $ (reward) depends only on the immediately preceding state and action, $ s $ and $ a $, and, given them, not at all on earlier states and actions. In other words, given the present, the future is independent of the past.
The state must include information about all aspects of the past agent–environment interaction that make a difference for the future. If it does, then the state is said to have the Markov property
If the transition dynamics equation is fully known by the agent, it means an optimal policy can be computed without interacting with the environment. This is planning. Some kind of search algorithm can be used here.
When the environment is not fully known, the agent has to learn by interacting with the environment. i.e. learning. If an agent constructs a model of the environment , it is called model based RL, else it is called model free RL.
If you are building a self driving car, learning from real experience can be too expensive so you want to build a model of then environment which you can query for information to make decisions.
When an agent in state $ S_t $ takes an action $ A_t $ as prescribed by a policy $ \pi $, it transitions to a state $ S_{t+1} $ and receives a reward $ R_{t+1} $. The Agent interacting with the **MDP** environment thus gives rise to a sequence or trajectory
$$ S_0,A_0,R_1,S_1,A_1,R_2,S_2,… $$ The goal of an agent is to maximize the long term reward or return.
Long term reward or return is formally defined as the discounted sum of future rewards.
$$ G_t = R_{t+1} + \gamma R_{t+2} + \gamma R_{t+3} +… = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} $$
$$ = R_{t+1} + \gamma G_{t+1} $$
Value Functions
To navigate an environment optimally, we need the concept of a value function that comes in two flavors
- State Value Function
- Action Value Function
The State - Value function of a state $ s $ under a policy $ \pi $,is the expected return from following policy $ \pi $ when starting in state $ s $
$$ v_{\pi}(s) \doteq \mathbb{E}_{\pi}[G_t | S_t =s] $$
The Action-Value function is the value of taking action $ a $ in state $ s $ under policy $ \pi $ and thereafter following the policy $ \pi $
$$ q_{\pi}(s,a) \doteq \mathbb{E}_{\pi}[G_t| S_t =s ,A_t=a] $$
Bellman Equations
The above definitions of the state and action value functions suggest equations to evaluate them known as Bellman Equations.
The Bellman expectation equation for the state value function follows naturally from the above definition of the state value function.
$$ v_{\pi}(s) \doteq \mathbb{E}[G_t | S_t =s] = \mathbb{E}_{\pi}[R_{t+1} + \gamma G_{t+1} | S_t =s]$$
$$ = \sum_{a} \pi(a|s) \sum_{s’}\sum_{r} p(s’,r|s,a) \Big[ r + \gamma \mathbb{E}_{\pi}[G_{t+1}|S_{t+1} = s’]\Big] $$ $$ = \sum_{a} \pi(a|s) \sum_{s’,r} p(s’,r|s,a) [r + \gamma v_{\pi}(s’)] $$
This is easily understood from the backup diagram shown below.

The value of a state $ s $ is obtained by considering all possible paths to all possible successor states , and weighting the rewards obtained and value of these successor states by the probabilities of taking each path.
The Bellman expectation equation for the action value function is similarly given by
$$ q_{\pi}(s,a) \doteq \mathbb{E}_{\pi}[G_t| S_t =s ,A_t=a] $$ $$ = \mathbb{E}_{\pi}[R_{t+1} + \gamma G_{t+1} | S_t =s’,A_t=a’] $$
$$ = \sum_{s’,r} p(s’,r|s,a)[r + \gamma \sum_{a’} \pi(a'|s’)q_{\pi}(s’,a’)] $$
To make this idea concrete, we can calculate the state value functions for the simplified version of the example we covered in the previous blog post.We will assume that there is only a single player carrying out a series of actions following a random policy with an equal probability of taking either action - L or R
We will assume the discount factor $ \gamma = 1 $
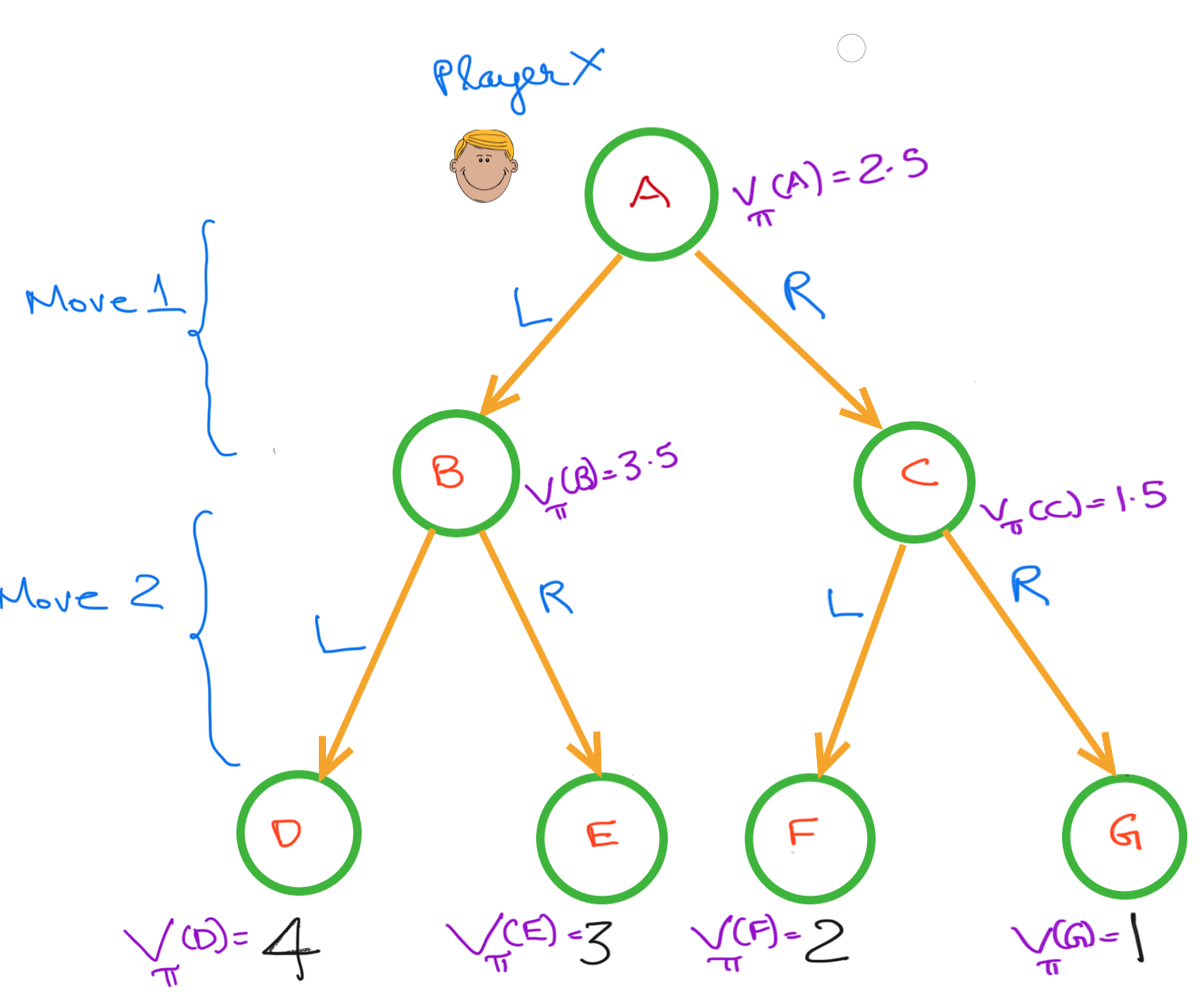
The value of any given state is derived from the value of the successor states.E.g. $$ V_{\pi}(B) = 0.5V_{\pi}(D) + 0.5 V_{\pi}(E) = 0.5 \times 4 + 0.5 \times 3 = 3.5 $$
Once the value of the successive states are known, the agent can pick the action that leads to the optimal state. In this example, the agent wants to move to state B, and takes action “L” to move to that state. A limitation of the state value function is that once you have determined the optimal state, you have to then identify the action that leads to that state.
The action value function does not have this limitation, it directly gives the value of each action at a given state making it easy to pick the optimal actions.
The action-value function at states B, C and A are given by
$$ Q(\mathcal{S}=B,\mathcal{A}=L) = 4 $$ $$ Q(\mathcal{S}=B,\mathcal{A}=R) = 3 $$ $$ Q(\mathcal{S}=C,\mathcal{A}=L) = 2 $$ $$ Q(\mathcal{S}=C,\mathcal{A}=R) = 1 $$ $$ Q(\mathcal{S}=A,\mathcal{A}=L) = 3.5 $$ $$ Q(\mathcal{S}=A,\mathcal{A}=R) = 1.5 $$
Optimal Policy
Theorem
For any MDP
- There exists an optimal policy $ \pi_* $, that is better than or equal to all other policies, $ \pi_* \ge \pi, \forall \pi $
- All optimal policies achieve the optimal value function $ v_{\pi_*} = v_*(s) $
- All optimal policies achieve optimal action-value function, $ q_{\pi_*}(s,a) = q_*(s,a) $
An optimal policy can be found by maximizing over the optimal value function $$ \pi_*(s) = \underset{a} \arg\max q_*(s,a) $$
$ q_*(s,a) $ is given by the **Bellman optimality equations**.
The Bellman Optimality equation for state values is given by
$$ v_*(s) = \max_{a} \sum_{s’,r} p(s’,r|s,a) [r + \gamma v_{\pi}(s’)] $$
The Bellman Optimality equation for action-values is given by
$$ q_{*}(s,a) = \sum_{s’,r} p(s’,r|s,a)[r + \gamma\ \underset{a’}max \ \pi(a'|s’)q_{\pi}(s’,a’)] $$
All RL algorithms solve for the Bellman Equations exactly or approximately. To solve the Tic-Tac-Toe, I will use an algorithm called Q-Learning. I will not not go into details of Q-Learning as there are plenty of free online resources that cover this.
Design
To solve this problem I will create a TicTacToe class that represents the board as a player sees it. Each of the two players retain their own copy of the board. This is possibly an inefficient design, but this is what I will run with.
Given tic-tac-toe is a 2 player game, I essentially simulate two different environments. In the first one, the agent is player X and in the second one the agent is player Y.
After the agent plays, the move by the opposing player is considered a change in the environment resulting from the agent’s actions. The new state the agent lands in is a board where the opposing player has already made his/her move.
import numpy as np
from itertools import product
import pandas as pd
import random
from collections import defaultdict
from tqdm import tqdm
from collections import Counter
import seaborn as sns
from matplotlib import pyplot as plt
class TicTacToe():
def __init__(self,player = 'X',reward_type ='goal_reward'):
'''
player: Role agent should play. If X, agent has the first turn else agent has second turn
reward_type: 'goal_reward' or 'action_penalty'
'''
self.board = np.array(['__']*9).reshape(3,3)
self.reward_type = reward_type
self.winning_seqeunce = None #Keep track of winning move made by agent
self.first_move = None #Keep track of first move made by agent
if player == 'X':
self.me ='X'
self.id = 1
self.opponent = 'O'
else:
self.me = 'O'
self.id = 2
self.opponent = 'X'
self.game_over = False #Flag indicating whether game is over
# Mapping of action representation in board to action representation in tuple
self.b_to_s = {'__':0,'X':1,'O':2}
# Mapping of action representation in tuple to action representation in board
self.s_to_b = {0:'__',1:'X',2:'O'}
#Create mapping from 2D position in board to 1D position in tuple
positions = self.available_positions()
self.b2_to_s1 = {position:i for (i,position) in enumerate(positions)}
#Create mapping from 1D position in tuple to 2D position in board
self.s1_to_b2 = {i:position for (i,position) in enumerate(positions)}
#State the current player is in
self.starting_state = self.board_to_state()
#Initialize all possible states of the game
l_o_l = [list(range(3)) for _ in range(9)]
states = set(product(*l_o_l))
#Player X states include states with odd number of blanks and both players have occupied equal number of slots
#Player O players after Player X, so player O states include states with even number of blanks and where
#player X has occupied one more slot than player O
playerX_states = {state for state in states if (state.count(0)%2 == 1 and state.count(1)==state.count(2))} #
playerO_states = {state for state in states if (state.count(0)%2 == 0 and state.count(1)==(state.count(2)+1))}
#States
#self.board_full_states = {state for state in states if state.count(0)==0}
if player == 'X':
self.my_states = playerX_states
else:
self.my_states = playerO_states
def reset_board(self):
"Function to reset game and reset board to starting state"
self.board = np.array(['__']*9).reshape(3,3)
self.starting_state = self.board_to_state()
self.game_over = False
self.winning_sequence = None
self.first_move = None
def show_board(self):
"Shows board as a pandas dataframe"
return pd.DataFrame(self.board)
def board_to_state(self):
"Convert a board to a state in tuple format"
return tuple([self.b_to_s[x] for x in np.ravel(self.board)])
@staticmethod
def possible_actions(state):
"Return possible actions given a state"
return [i for i,x in enumerate(state) if x ==0]
def is_game_over(self):
"Function to check if game is over"
if not np.any(self.board == '__') :
self.game_over = True
return self.game_over
def available_positions(self):
"Return available positions on the board"
x,y = np.where(self.board =='__')
return[(x,y) for x,y in zip(x,y)]
def win(self,player):
"Check if player won the game and record the winning sequence"
if np.all(self.board[0,:] == player):
self.winning_sequence = 'R1'
elif np.all(self.board[1,:] == player):
self.winning_sequence = 'R2'
elif np.all(self.board[2,:] == player):
self.winning_sequence = 'R3'
elif np.all(self.board[:,0] == player):
self.winning_sequence = 'C1'
elif np.all(self.board[:,1] == player):
self.winning_sequence = 'C2'
elif np.all(self.board[:,2] == player):
self.winning_sequence = 'C3'
elif np.all(self.board.diagonal()==player):
self.winning_sequence = 'D1'
elif np.all(np.fliplr(self.board).diagonal()==player):
self.winning_sequence = 'D2'
else:
return False
return True
def my_move(self,position):
"Fills out the board in the given position with the action of the agent"
assert position[0] >= 0 and position[0] <= 2 and position[1] >= 0 and position[1] <= 2 , "incorrect position"
assert self.board[position] == "__" , "position already filled"
assert np.any(self.board == '__') , "Board is complete"
assert self.win(self.me) == False and self.win(self.opponent)== False , " Game has already been won"
self.board[position] = self.me
I_win = self.win(self.me)
opponent_win = self.win(self.opponent)
if self.reward_type == 'goal_reward':
if I_win:
self.game_over = True
return 1
elif opponent_win:
self.game_over = True
return -1
else:
return 0
elif self.reward_type == 'action_penalty':
if I_win:
self.game_over = True
return 0
elif opponent_win:
self.game_over = True
return -10
else:
return -1
def opponent_move(self,position):
"Fills out the board in the given position with the action of the opponent"
assert position[0] >= 0 and position[0] <= 2 and position[1] >= 0 and position[1] <= 2 , "incorrect position"
assert self.board[position] == "__" , "position already filled"
assert np.any(self.board == '__') , "Board is complete"
assert self.win(self.me) == False and self.win(self.opponent)== False , " Game has already been won"
self.board[position] = self.opponent
def pick_best_action(self,Q,action_type,eps=None):
'''Given a Q function return optimal action
If action_type is 'greedy' return best action with ties broken randomly else return epsilon greedy action
'''
#Get possible actions
current_state = self.board_to_state()
actions = self.possible_actions(current_state)
best_action = []
best_action_value = -np.Inf
for action in actions:
Q_s_a = Q[current_state][action]
if Q_s_a == best_action_value:
best_action.append(action)
elif Q_s_a > best_action_value:
best_action = [action]
best_action_value = Q_s_a
best_action = random.choice(best_action)
if action_type == 'greedy':
return self.s1_to_b2[best_action]
else:
assert eps != None , "Include epsilon parameter"
n_actions =len(actions) #No of legal actions
p = np.full(n_actions,eps/n_actions)
#Get index of best action
best_action_i = actions.index(best_action)
p[best_action_i]+= 1 - eps
return self.s1_to_b2[np.random.choice(actions,p=p)]
Below is a demonstration of how this class works. Let us assume the we are training Player X to play the game.
t_board_X = TicTacToe(player = 'X',reward_type ='goal_reward')
t_board_X.show_board()
## 0 1 2
## 0 __ __ __
## 1 __ __ __
## 2 __ __ __
We will alternate between moves for X(player) and O(opponent) until the game ends with player X winning
t_board_X.my_move((0,0))
## 0
t_board_X.show_board()
## 0 1 2
## 0 X __ __
## 1 __ __ __
## 2 __ __ __
t_board_X.opponent_move((0,1))
t_board_X.show_board()
## 0 1 2
## 0 X O __
## 1 __ __ __
## 2 __ __ __
t_board_X.my_move((1,0))
## 0
t_board_X.opponent_move((1,1))
t_board_X.my_move((2,0))
## 1
t_board_X.show_board()
## 0 1 2
## 0 X O __
## 1 X O __
## 2 X __ __
Utility Functions
The following primary utility functions will be used. Please refer to the jupyter notebook for the definitions of these functions
play_games:This function simulates games between the two players a specified number of times and returns relevant statistics from the gameget_win_statistics: This functions simulates the specified number of games N times(equivalent to sets in a tennis game) and returns statistics collected across these setsplot_results: This function visualizes the statistics collectedinitialize_Q: Randomly initialize a Q table for the given playertrain: Function to train the agent using the Q-Learning algorithm
Experiments
I will run the following experiments to evaluate how well the agent has learned
- Random X vs Random O
- Trained X vs Random O
- Random X vs Trained O
- Trained X vs Trained O
- Re-trained X vs Trained O
Random X vs Random O
As a baseline, let us see how the results look like when both players follow a random policy. We will maintain two separate boards for each of the players.
t_board_X = TicTacToe(player = 'X',reward_type ='goal_reward')
t_board_O = TicTacToe(player = 'O',reward_type ='goal_reward')
We will first enumerate the states for both sets of players.
States_X = t_board_X.my_states
States_O = t_board_O.my_states
Create a Q-table for both.
Q_X = initialize_Q(States_X)
Q_O = initialize_Q(States_O)
Let us see what the results look like over 1000 games.
win_statistics = get_win_statistics(Q_X, Q_O,sets = 10, games_in_set = 100, X_strategy ='eps_greedy',O_strategy='eps_greedy',eps_X=1.0,eps_O=1.0)
# Setting eps = 1.0 ensures purely random policy
plot_results(win_statistics)
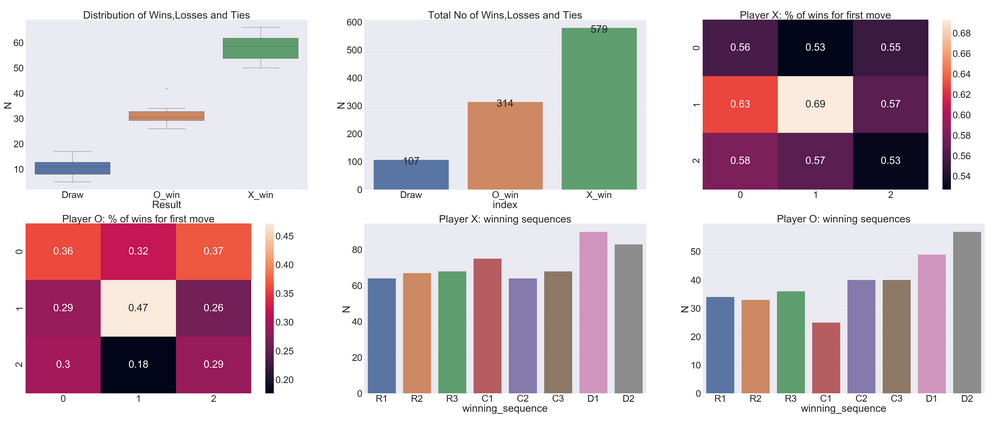
It seems like X typically wins around 60% of games.
As expected X wins more games than O as it gets to start first and make more moves than O. For both players, occupying the central square in the first move maximizes the chances of winning.
Further, for both players, the winning sequence is most likely to be along the diagonal.
Trained X vs Random O
Now we will train X to play optimally against a random O.
np.random.seed(1)
Q_X,_,rewards_X,rewards_O = train(n_games=5000,alpha = 0.5, gamma = 0.9,train_X=True,train_O=False,is_random=True)

Q_X_trained = Q_X #Save trained X
The learning curve indicates the training has converged after around 4000 games.
win_statistics = get_win_statistics(Q_X_trained,Q_O,sets = 5, games_in_set = 100,X_strategy = 'greedy',O_strategy='eps_greedy',eps_X=1.0,eps_O=1.0)
plot_results(win_statistics)

These results indicate that player X has learned to easily beat a random player O. Player X consistently chooses the top right hand box and seem to win the majority of games through the right most column (C3) or the off diagonal(D2).
Random X vs Trained O
Now we will train O to play against a random X
np.random.seed(1)
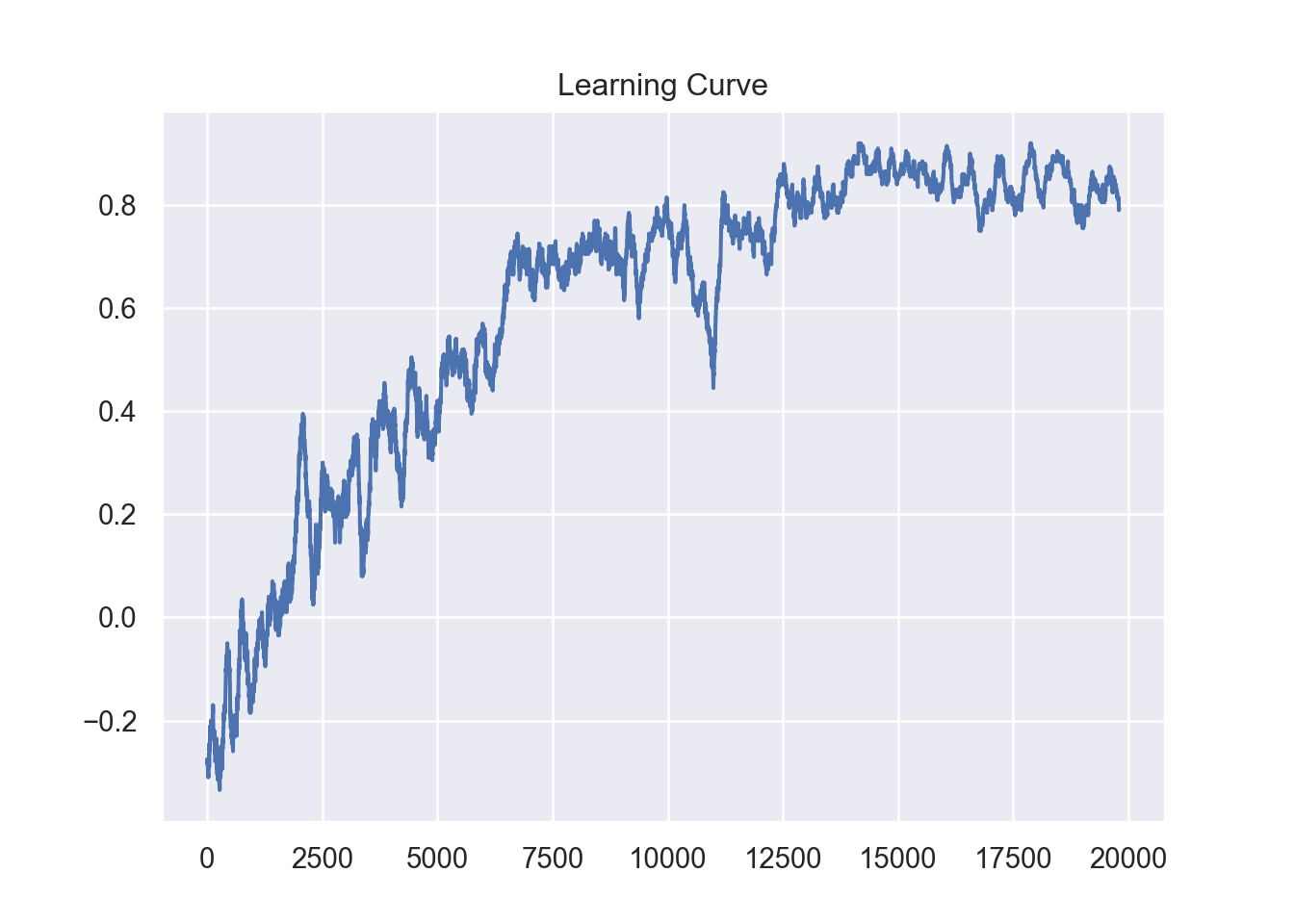
_,Q_O,rewards_X,rewards_O = train(n_games=20000,alpha = 0.5, gamma = 0.5,train_X=False,train_O=True,is_random=True)
Q_O_trained = Q_O #Save trained O
The learning curve indicates training has converged after about 15000 games.
win_statistics = get_win_statistics(Q_X,Q_O_trained,sets = 10, games_in_set = 100,X_strategy = 'eps_greedy',O_strategy='greedy',eps_X=1.0,
eps_O=1.0)
plot_results(win_statistics)

The above results indicate that Player O has learned to consistently beat the random player X. What is interesting to note is that the RL approach results in Player O beating Player X more consistently (85%) of the time than when using the Minimax approach (~ 81%).
We can also see the player O consistently picks boxes along the leading diagonal as its first move. Most of its wins come from occupying the leading diagonal(D1) or the middle column(C2).
Trained X vs Trained O
Now we will pit the two trained players against each other.
win_statistics = get_win_statistics(Q_X_trained,Q_O_trained,sets = 10, games_in_set = 100,X_strategy = 'greedy',O_strategy='greedy',eps_X=1.0,
eps_O=1.0)
plot_results(win_statistics)

When the two trained agents face off, all games end in ties.
Retrained X vs Trained O
Initially we trained X against a random O, now we will retrain X against a trained O
np.random.seed(1)
Q_X,Q_O,rewards_X,rewards_O = train(n_games=1000,alpha = 0.5, gamma = 0.9,train_X=True,train_O=False,is_random=False,Q_O = Q_O_trained)

Q_X_retrained = Q_X
In this case , given player O is following a deterministic policy, training converges in just 500 games.
win_statistics= get_win_statistics(Q_X_retrained,Q_O_trained,sets = 10, games_in_set = 100,X_strategy = 'greedy',\
O_strategy='greedy',eps_X=1.0,eps_O=1.0)
plot_results(win_statistics)

The re-trained player X beats the trained Player in 100% of the games.
Conclusion
Reinforcement learning is a powerful paradigm in AI that can potentially be the key to solving several real world problems. Although the early days of RL has seen an almost exclusively focus on games, there are several practical applications of RL outside of games that industry is working on. At Oracle, we are working on a potentially category defining product that uses reinforcement learning at its core. Watch this space for more!